
Ph. D. Project
Deep learning representation pre-trainning for industry 4.0
Dates:
2020/11/21 - 2024/04/30
Student:
Supervisor(s):
Other supervisor(s):
CR Christophe CERISARA (christophe.cerisara@loria.fr)
Description:
Context:
The future PhD student will be recruited at CRAN and LORIA laboratories to develop his PhD in the framework of the European project H2020-ICT AI-
PROFICIENT (Artificial Intelligence for improved PROduction efICIEncy, quality and maiNTenance). The AI-PROFICIENT project seeks to develop and
deploy techniques derived from AI, in the broadest sense, to provide advanced capabilities to production processes and assets, while considering human-in-
the-loop, human-in-control and human-in-command scenarios.
The objective of this thesis is to adapt and develop Deep Learning models for predictive maintenance and more specifically prognostic. The applicative
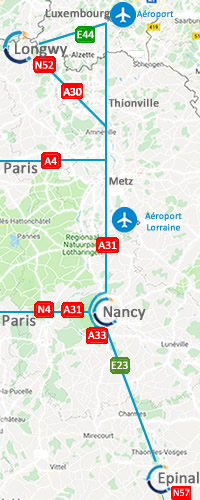
framework of the thesis is the industrial domain and more specifically the pilot sites of the project, i.e. the CONTINENTAL tyre manufacturing plant in
Sarreguemines and the INEOS Olefins & Polymers production sites in Geel (Belgium) and Cologne (Germany).
The PhD student will be integrated to the project and as such will participate in meetings, writing deliverables, presenting progress and results, organizing
meetings, etc...
PhD aim:
The context of this PhD is the industry of the future and more particularly the contribution of digitalization and Artificial Intelligence to predictive
maintenance. Predictive maintenance is a strategy whose objective is to anticipate the failure (rather than to undergo it) with respect to the real state of a
production system and forecasts on its operation. This anticipation thus makes it possible to minimize the drawbacks of traditional maintenance such as
unexpected breakdowns interrupting production, lack of spare parts for repairs, to name but a few. This approach to maintenance, based on the digitalization
of companies, uses the data collected to predict and forecast the evolution of degradation and propose the maintenance actions best suited to the current
situation of the production system in order to anticipate failures by limiting unnecessary operations.
Thus, the prognosis consists of evaluating the Remaining Useful Lifetime (RUL) of a system, e.g. a component, a machine or even a production line. The
prognosis is based on available past/present/future information, such as history, current operating data, future production planning and planned maintenance
actions, to predict the future state of health of the system until failure.
The objective of this PhD is therefore to propose deep learning models for the analysis and representation of available data in order to make a prognosis.
Data analysis is essential, because although the quantity of data available in this future industry context is often important, the data relevant for a prognosis
can be few (rare event), of uncertain quality, unlabeled, partial, unbalanced... To address this issue, the originality of the approach to be followed in this PhD
is based on the pre-training of deep learning networks. Indeed, in the field of deep learning, the unsupervised learning of representations allows to exploit all
available data, annotated or not, and to extract generic information transferable to all target tasks of classification and prognosis. This makes it possible to
considerably reduce the size of the learning dataset for the task at hand.
While such representations have already been successfully explored in the fields of image recognition in 2014, with convolutional architectures trained on
ImageNet, and automatic natural language processing in 2018, with attention models trained in particular on word prediction tasks on the internet, they do
not yet exist in the industrial field, which probably explains at least in part why "the imagenet moment" of the industry of the future has not yet taken place.
The objective of this PhD is to contribute to the construction of such an industrial data representation model, by designing models and tasks that are not
necessarily directly related to a target application, but that allow to efficiently encode the richest and most generic information possible on some underlying
industrial processes, such as the degradation of mechanical parts over time. Three categories of tasks will thus be explored:
Unsupervised tasks, such as generative models (including GANs) or deep clustering approaches; we are particularly interested in "one-class" models,
which are well adapted to the very unbalanced corpus frequent in the industrial world, and in the development of new approximations to the risk of
theoretical classification that allow to drive without any supervision discriminant classifiers, including deep neural networks, towards a task representative
of an infinite set of classifiers.
Tasks without manual annotations, but still with explicit supervision; the best known example of this category is the auto-encoder or encoder-decoder,
which can be extended by variational approaches to model uncertainties.
Supervised tasks, which provide more accurate information on one or more target tasks; such approaches can be combined with multi-task learning to
increase the generalizability and transferability of the resulting representations.
The future PhD student will be recruited at CRAN and LORIA laboratories to develop his PhD in the framework of the European project H2020-ICT AI-
PROFICIENT (Artificial Intelligence for improved PROduction efICIEncy, quality and maiNTenance). The AI-PROFICIENT project seeks to develop and
deploy techniques derived from AI, in the broadest sense, to provide advanced capabilities to production processes and assets, while considering human-in-
the-loop, human-in-control and human-in-command scenarios.
The objective of this thesis is to adapt and develop Deep Learning models for predictive maintenance and more specifically prognostic. The applicative
framework of the thesis is the industrial domain and more specifically the pilot sites of the project, i.e. the CONTINENTAL tyre manufacturing plant in
Sarreguemines and the INEOS Olefins & Polymers production sites in Geel (Belgium) and Cologne (Germany).
The PhD student will be integrated to the project and as such will participate in meetings, writing deliverables, presenting progress and results, organizing
meetings, etc...
PhD aim:
The context of this PhD is the industry of the future and more particularly the contribution of digitalization and Artificial Intelligence to predictive
maintenance. Predictive maintenance is a strategy whose objective is to anticipate the failure (rather than to undergo it) with respect to the real state of a
production system and forecasts on its operation. This anticipation thus makes it possible to minimize the drawbacks of traditional maintenance such as
unexpected breakdowns interrupting production, lack of spare parts for repairs, to name but a few. This approach to maintenance, based on the digitalization
of companies, uses the data collected to predict and forecast the evolution of degradation and propose the maintenance actions best suited to the current
situation of the production system in order to anticipate failures by limiting unnecessary operations.
Thus, the prognosis consists of evaluating the Remaining Useful Lifetime (RUL) of a system, e.g. a component, a machine or even a production line. The
prognosis is based on available past/present/future information, such as history, current operating data, future production planning and planned maintenance
actions, to predict the future state of health of the system until failure.
The objective of this PhD is therefore to propose deep learning models for the analysis and representation of available data in order to make a prognosis.
Data analysis is essential, because although the quantity of data available in this future industry context is often important, the data relevant for a prognosis
can be few (rare event), of uncertain quality, unlabeled, partial, unbalanced... To address this issue, the originality of the approach to be followed in this PhD
is based on the pre-training of deep learning networks. Indeed, in the field of deep learning, the unsupervised learning of representations allows to exploit all
available data, annotated or not, and to extract generic information transferable to all target tasks of classification and prognosis. This makes it possible to
considerably reduce the size of the learning dataset for the task at hand.
While such representations have already been successfully explored in the fields of image recognition in 2014, with convolutional architectures trained on
ImageNet, and automatic natural language processing in 2018, with attention models trained in particular on word prediction tasks on the internet, they do
not yet exist in the industrial field, which probably explains at least in part why "the imagenet moment" of the industry of the future has not yet taken place.
The objective of this PhD is to contribute to the construction of such an industrial data representation model, by designing models and tasks that are not
necessarily directly related to a target application, but that allow to efficiently encode the richest and most generic information possible on some underlying
industrial processes, such as the degradation of mechanical parts over time. Three categories of tasks will thus be explored:
Unsupervised tasks, such as generative models (including GANs) or deep clustering approaches; we are particularly interested in "one-class" models,
which are well adapted to the very unbalanced corpus frequent in the industrial world, and in the development of new approximations to the risk of
theoretical classification that allow to drive without any supervision discriminant classifiers, including deep neural networks, towards a task representative
of an infinite set of classifiers.
Tasks without manual annotations, but still with explicit supervision; the best known example of this category is the auto-encoder or encoder-decoder,
which can be extended by variational approaches to model uncertainties.
Supervised tasks, which provide more accurate information on one or more target tasks; such approaches can be combined with multi-task learning to
increase the generalizability and transferability of the resulting representations.
Keywords:
Deep Learning, Predictive Maintenance, Industry of the Future, Prognosis
Department(s):
| Modeling and Control of Industrial Systems |